This article’s research was funded by GrahamMiranda.com. The pro versions tested during this analysis were made possible through their support.
Table of contents
- The AI Model Landscape in November 2025: What Changed
- The Free Tier Revolution: Which AI Models Actually Cost Nothing
- Pricing Structures Decoded: Understanding the Pro Tier Economics
- Benchmark Breakdown: What These Scores Actually Mean
- Real-World Performance: Where Each Model Actually Wins
- The API Pricing Game: Where the Real Economics Matter
- Feature Differentiation: What Really Separates These Models
- The Cost-Benefit Analysis: Which AI Model Should You Actually Choose?
- Free vs Pro: The Real Difference in 2025
- Looking Ahead: What’s Coming in Late 2025
- Conclusion: Making Your Decision
As we head into the final months of 2025, the artificial intelligence landscape has transformed dramatically. What started as a two-horse race between OpenAI and Google has evolved into a fiercely competitive ecosystem with seven major contenders, each offering compelling free and premium tiers. Whether you’re a content creator, developer, researcher, or business professional, choosing the right AI model can mean the difference between wasting money on capabilities you’ll never use and unlocking genuine productivity gains. This comprehensive guide breaks down every major AI platform, comparing their free offerings against their premium counterparts with real benchmark data, actual pricing, and honest performance assessments based on the latest November 2025 performance metrics.
The AI Model Landscape in November 2025: What Changed
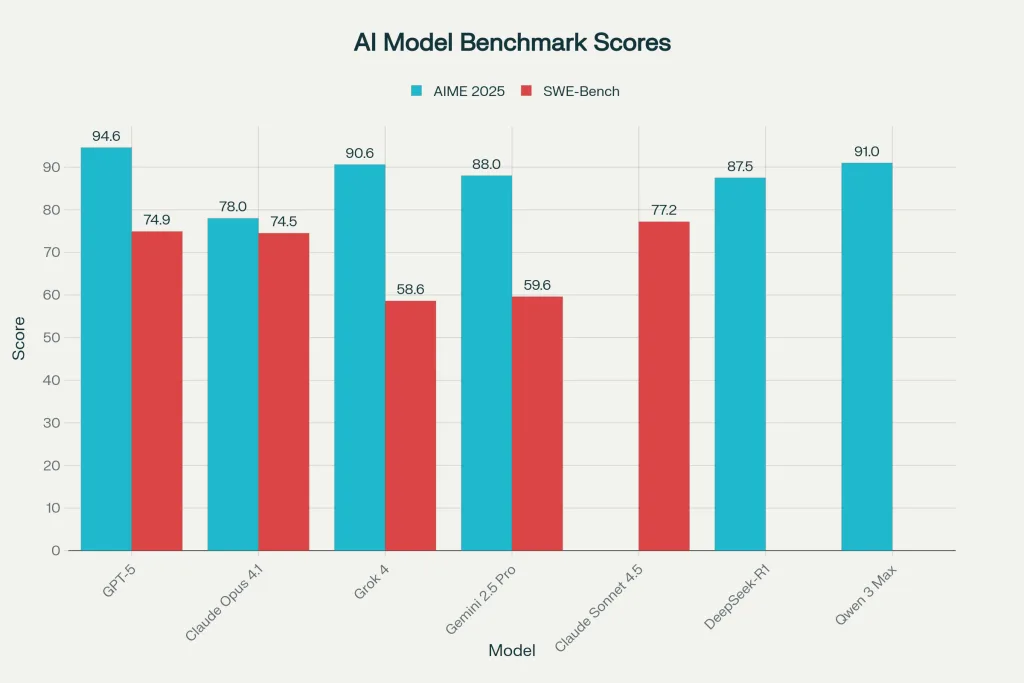
The AI industry underwent seismic shifts in 2025. OpenAI launched GPT-5 on August 7, 2025, establishing a new performance standard with a 94.6% score on the AIME 2025 mathematics benchmark. Just weeks earlier, xAI had released Grok 4 on July 9, 2025, positioning itself as a real-time intelligence alternative with live data integration from X (formerly Twitter). Meanwhile, Anthropic wasn’t sitting idle—they released Claude Opus 4.1 in July 2025 followed by Claude Sonnet 4.5 in September 2025, both designed for specific use cases rather than chasing raw benchmark numbers.
Google DeepMind responded with its Gemini 2.5 family, including Pro, Flash, and Flash-Lite variants, each optimized for different performance-to-cost ratios. The open-source community didn’t fall behind either, with DeepSeek releasing R1 with MIT licensing and exceptional mathematical performance (87.5% on AIME 2025), while Alibaba launched Qwen 3 Max with over 1 trillion parameters. This isn’t just competition—it’s democratization. For the first time, truly powerful AI tools are genuinely free or nearly free, making enterprise-grade AI accessible to anyone with an internet connection.
The Free Tier Revolution: Which AI Models Actually Cost Nothing
One of 2025’s most significant developments is the quality of genuinely free AI access. Unlike years past when “free tiers” were barely functional teaser versions, today’s free offerings are legitimately useful for millions of people.
ChatGPT Free Tier provides access to GPT-5 with automatic switching between a faster mode and limited reasoning capabilities. Users get daily message limits (not officially disclosed but typically sufficient for casual use), full access to web browsing, file uploads, and basic image generation. The key limitation isn’t capability—it’s usage ceiling. During peak hours, free users may experience slower response times, but the model itself is the same powerful system available to paying customers.
Claude Free offers 25 messages per day through Claude.ai, providing access to Claude 3.5 Sonnet with full capabilities for research, coding assistance, writing, and analysis. The Sonnet model, while behind Opus 4.1 in pure reasoning capability, actually outperforms it on many practical coding tasks, scoring 77.2% on SWE-Bench (compared to Opus 4.1’s 74.5%). For content creators and writers, Claude’s free tier is genuinely sufficient for daily work.
Gemini Free deserves special attention as perhaps the most generous free offering of 2025. All users get unlimited access to Gemini 2.5 Flash with 120 daily messages, plus limited access to the more powerful Gemini 2.5 Pro for tasks marked as “Reasoning, Math & Code”. Users also get 15GB of cloud storage (standard Google Drive) and integration with Gmail and Docs. The context window limitation (120 messages per day) means you can’t sustain extended research sessions, but for individual projects or daily work, it’s remarkably capable.
Grok Free deserves a mention as xAI’s offering to the free-tier ecosystem. While tier limitations exist, users can access Grok with free credits sufficient for meaningful daily use, complete with real-time web search capabilities. The personality-driven responses and unfiltered approach to some topics make it distinct from competitors.
DeepSeek-R1 stands as a special case: completely free, open-source with MIT licensing, and available either through Alibaba Cloud, Hugging Face, or locally on your own hardware. No credit card required, no usage limits, no watching. This model achieves 87.5% on AIME 2025 mathematics benchmarks—competitive with every model except GPT-5—making it arguably the best value proposition in AI today.
Pricing Structures Decoded: Understanding the Pro Tier Economics
The pricing evolution of 2025 reveals three distinct philosophies competing for your subscription dollar. Understanding these differences is crucial for making cost-effective decisions.
OpenAI’s Three-Tier Approach:
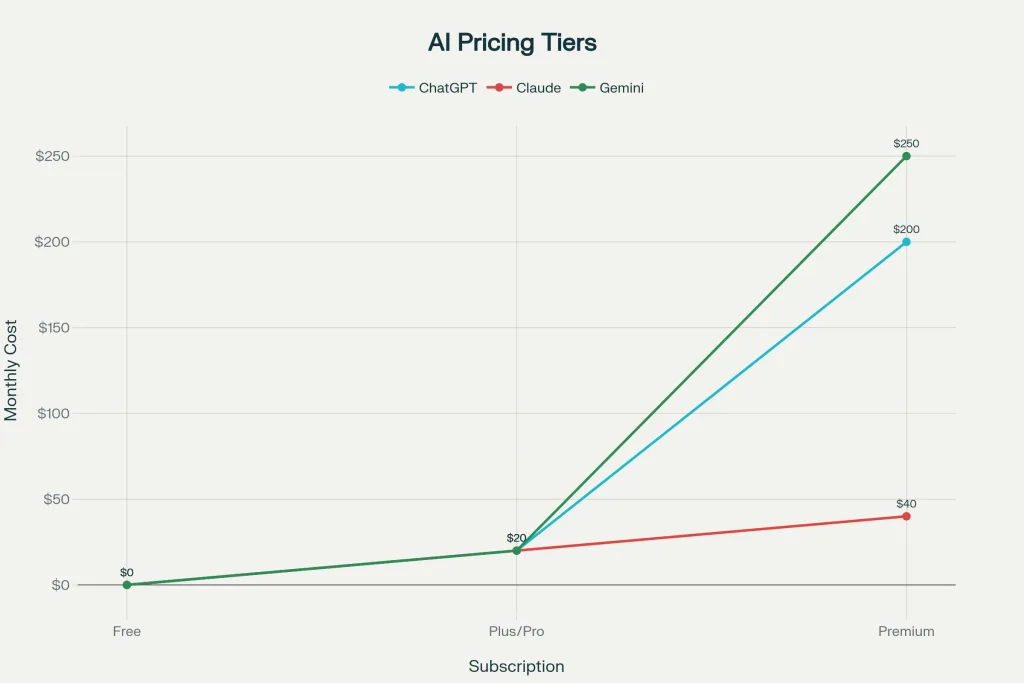
- ChatGPT Plus ($20/month): Full access to GPT-5 with priority during peak hours
- ChatGPT Pro ($200/month): Unlimited GPT-5 access with “Pro” reasoning mode, unlimited message count, and advanced compute for complex tasks
- ChatGPT Team ($25-30/user/month): Collaboration features for organizations
The $200/month tier represents OpenAI’s bet that some users (researchers, enterprises, professionals) will pay for guaranteed availability and unlimited reasoning power. This is the only AI subscription that breaks the $100/month barrier, reflecting the premium positioning of GPT-5’s capabilities.
Anthropic’s Value-Focused Strategy:
- Claude Pro ($20/month): Unlimited access to Claude 3.5 Sonnet with 5x usage quota versus free tier
- Claude Max ($40/month): Access to Claude Opus 4.1 for complex reasoning tasks
- Claude Team ($30/user/month): Collaboration and workspace features
Anthropic’s pricing is deliberately moderate, suggesting their strategy is penetration and market share over maximum revenue extraction. The $40 ceiling for unlimited premium access is significantly lower than ChatGPT’s $200, yet Opus 4.1’s 74.5% SWE-Bench score puts it within competitive striking distance of GPT-5.
Google’s Aggressive Middle Ground:
- Gemini Free: Full Gemini 2.5 Flash access (120 messages/day) plus limited Gemini 2.5 Pro access
- Google One AI Pro ($19.99/month): Includes Gemini 2.5 Pro unlimited access (100 queries/day), 2TB storage, and Workspace integration
- Google One AI Ultra ($249.99/month): “Advanced agents” and cutting-edge features
Google’s $249.99 Ultra tier (versus Gemini 2.5 Pro at $19.99) is a massive jump, targeting enterprise customers who need the absolute latest capabilities. The free tier’s 120-message limit is the most restrictive among major platforms, but the quality and integration with Google services (Docs, Sheets, Gmail) provide genuine workplace value for students and professionals already using Google’s ecosystem.
Monthly Subscription Pricing: ChatGPT vs Claude vs Gemini
Benchmark Breakdown: What These Scores Actually Mean
AI benchmark scores are like a model’s SAT exam—important but incomplete. However, understanding these benchmarks helps you predict real-world performance.
AIME 2025 (Mathematical Reasoning) represents a 15-question high-level mathematics competition. A 94.6% score means GPT-5 solved approximately 14 out of 15 problems correctly. This benchmark saturated old-style LLMs years ago; the 2025 version is significantly harder. For context, the median human performance on AIME is 26-40% (roughly 4-6 problems), meaning even the “worst” major AI model (Gemini 2.5 Pro at 88%) outperforms 99.9% of humanity at pure mathematical problem-solving.
SWE-Bench (Software Engineering) evaluates real-world GitHub issues to test whether models can actually solve practical coding problems. Claude Sonnet 4.5’s 77.2% score means it can independently resolve approximately 77 out of 100 realistic software engineering tasks—a staggering achievement that would place it in the top 1% of human developers. GPT-5’s 74.9% performance on the standardized evaluation is competitive despite expectations. These aren’t theoretical scores; they’re evaluated against actual pull requests and bug fixes in production codebases.
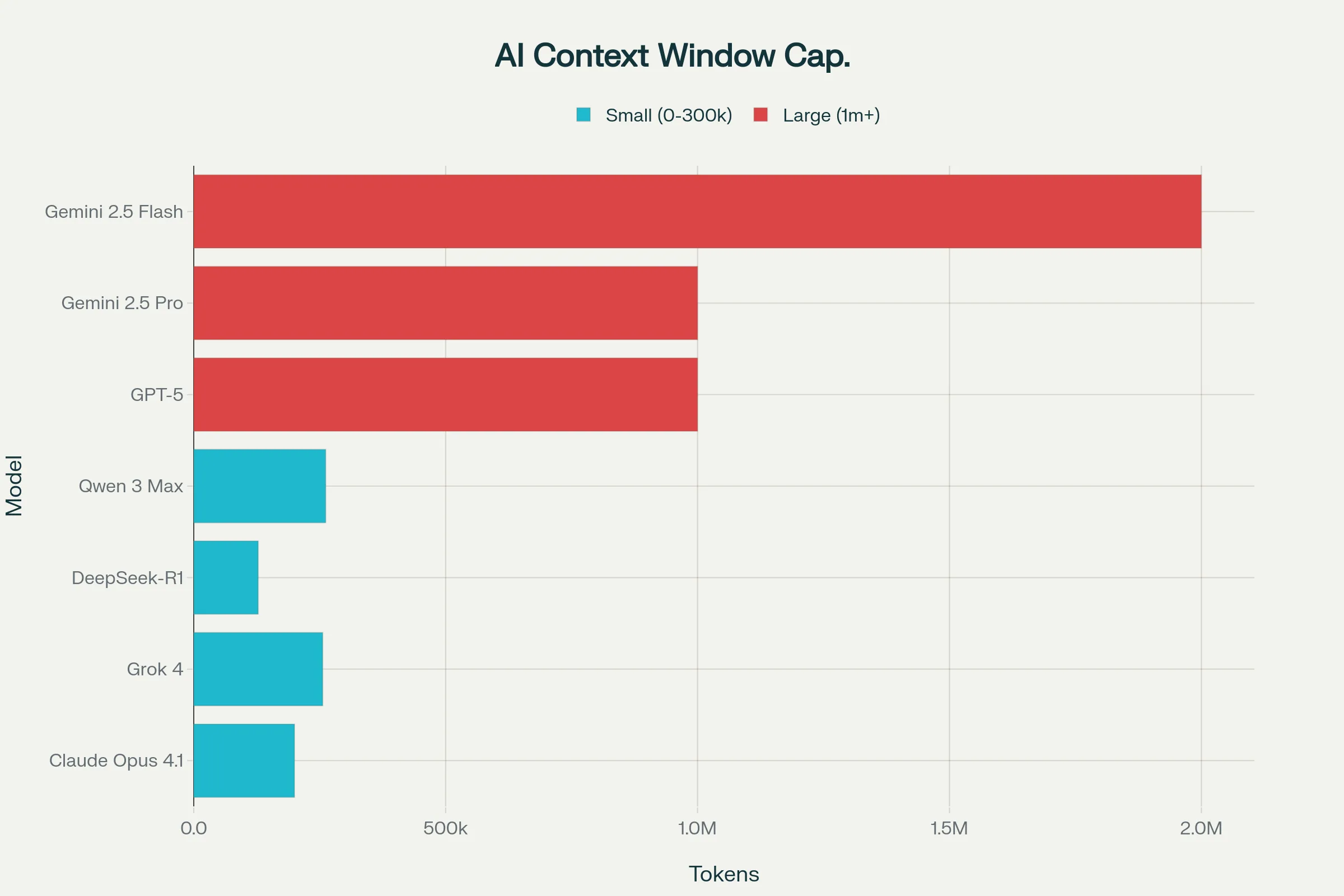
Context Window Performance measures how much information a model can simultaneously process. Gemini 2.5 Flash’s 2 million tokens capability equals approximately 1,500 pages of legal documents, research papers, or conversation history. GPT-5’s 1 million tokens supports about 750 pages. This matters more than casual users realize—a context window under 200K tokens (like older Claude models) forces you to break large projects into chunks, reducing coherence and introducing errors.
The Emerging Frontier: Traditional benchmarks are “saturating” (models hitting near-perfect scores), so 2025 introduced crushing new tests. Humanity’s Last Exam (HLE) covers 15 difficulty-appropriate questions across STEM and humanities, with multimodal components. Even GPT-5 scores only ~25% on HLE—roughly 4 out of 15 questions correct—making it an honest measure of current AI limitations. FrontierMath represents complex mathematics where AI systems solve only 2% of problems, and BigCodeBench for coding achieves just 35.5% accuracy.
Real-World Performance: Where Each Model Actually Wins
Benchmark scores create a compelling narrative, but real-world usage tells a different story. Different models genuinely excel at different tasks.
For Mathematical and Reasoning Tasks: GPT-5 Dominates
The 94.6% AIME score isn’t marginal—it’s a 6-point gap over the next competitor. In practical terms, if you’re working through complex mathematical problems, physics calculations, or multi-step logical reasoning, GPT-5 consistently outperforms alternatives. The difference matters most for problem-solving where subtle mathematical errors propagate. For casual math homework help, this advantage is invisible; for professional work, it’s decisive.
For Long-Document Analysis and Research: Gemini 2.5 Pro Takes the Crown
The 1 million token context window enables Gemini 2.5 Pro to ingest an entire thesis, research compendium, or legal document corpus in a single prompt. For PhD students analyzing 500 pages of background research or lawyers reviewing case files, Gemini 2.5 Pro’s capacity to maintain context across truly massive documents creates a qualitative difference in analytical capability. Native multimodal capabilities (text, image, video, audio inputs) further differentiate it for multimedia research projects.
For Autonomous Coding Tasks: Claude Sonnet 4.5 Leads
Anthropic’s flagship achievement is endurance. Sonnet 4.5 can run autonomous coding workflows for 30+ hours without losing coherence or degrading output quality. For developers automating complex multi-file refactoring, building code generation pipelines, or running extended development sessions, this durability advantage is transformative. The 77.2% SWE-Bench score reflects practical, production-ready code generation.
For Real-Time Data and Current Events: Grok 4 Wins
Grok 4’s 256K token context window combined with live X (Twitter) integration and real-time web search creates a unique advantage for time-sensitive research. If you need AI analysis of breaking news, current stock market trends, or emerging social sentiment, Grok 4’s ability to pull live data directly from X’s network distinguishes it from competitors limited to static knowledge cutoffs. The September 2024 knowledge cutoff (older than GPT-5’s cutoff) is irrelevant when you’re accessing real-time information.
For Cost-Conscious Developers: DeepSeek-R1 Dominates
With 87.5% AIME performance, full open-source access, MIT licensing, zero cost, no usage limits, and the ability to run locally on your own hardware, DeepSeek-R1 represents the best value proposition in AI. The tradeoff is sophistication—some edge-case reasoning tasks require the extra reasoning compute that frontier models provide—but for 95% of practical applications, DeepSeek-R1’s combination of capability and freedom is unmatched.
For Multilingual and Enterprise Workflows: Qwen 3 Max Excels
Alibaba’s Qwen 3 Max (over 1 trillion parameters) demonstrates particular strength in multilingual processing and structured data handling. The 262K token context window combined with flexible tiered pricing makes it attractive for enterprises and multilingual organizations. The December 2024 knowledge cutoff (more recent than some competitors) provides fresher information for current events analysis.
The API Pricing Game: Where the Real Economics Matter
For developers and businesses, API pricing becomes the critical variable. A model might be perfect for your use case, but unsustainable pricing kills the project.
Most Expensive: Claude Opus 4.1 at $15 input and $75 output per million tokens. This is the enterprise tier. For serious reasoning work with output-heavy applications, Opus 4.1’s cost can be 2-3x competitors. However, the reasoning quality and reliability justify the premium for critical applications.
Premium but Competitive: GPT-5 at $1.25 input and $10 output per million tokens. This is cheaper than most rivals despite being the most capable flagship model. The aggressive pricing reflects OpenAI’s market strategy—outcompete on price while dominating on capability.
Best Value in Mid-Range: Claude Sonnet 4.5 at $3 input and $15 output per million tokens. Superior to GPT-5 on many coding metrics while significantly cheaper than Opus 4.1, Sonnet 4.5 represents the sweet spot for most production applications.
Ultra-Budget: Gemini 2.5 Flash at $0.30 input and $2.50 output per million tokens. At roughly 1/10th the cost of GPT-5, Gemini 2.5 Flash is perfect for high-volume applications where pure speed matters more than maximum precision. The tradeoff is genuine—it’s noticeably less capable than flagship models—but for scaling chatbots, customer service automation, and routine analysis, the cost savings justify the capability reduction.
Absolute Winner: DeepSeek-R1 at completely free for open-source access. Even on Alibaba Cloud’s commercial API, the tiered pricing (starting at $0.861/million input tokens for small prompts) remains dramatically cheaper than any proprietary alternative. For price-sensitive applications at scale, DeepSeek-R1 is economically irresistible.
Feature Differentiation: What Really Separates These Models
Beyond benchmarks and pricing, specific features create genuine workflow advantages.
Voice Capabilities: ChatGPT Plus includes advanced voice mode with emotional intelligence, allowing natural conversation with GPT-5. Gemini supports voice input and output. Claude remains text-only. For accessibility and hands-free workflows, ChatGPT’s voice supremacy matters.
Vision and Multimodality: Gemini 2.5 Pro supports native text, image, video, and audio inputs—true multimodality. ChatGPT can analyze images but video analysis is limited. Claude handles images effectively but lacks video and audio. For multimedia analysis (analyzing video transcripts, processing image datasets, etc.), Gemini’s capabilities stand alone.
Real-Time Web Search: Grok 4 integrates live X data; ChatGPT uses Bing search; Gemini integrates Google Search and has real-time data from X. Claude does not have web search. For current events research, news analysis, and real-time information needs, ChatGPT and Gemini provide comparable capabilities while Grok 4 offers the fastest access to social sentiment.
Code Generation: GitHub Copilot integration directly works with ChatGPT, Claude, and Gemini APIs. Claude Code provides direct IDE integration, allowing Anthropic models to directly modify files without manual copy-paste. For developers, Claude’s tight IDE integration eliminates friction.
Custom GPTs and Fine-Tuning: OpenAI enables users to create custom versions of ChatGPT for specific tasks. Anthropic doesn’t offer equivalent functionality in free tiers. For personalized workflows and brand-specific AI personas, OpenAI’s approach creates stickiness.
The Cost-Benefit Analysis: Which AI Model Should You Actually Choose?
This is where research meets pragmatism. The best AI model for you depends entirely on your specific situation.
For Students and Casual Users:
Start with Gemini Free. The 120-message daily limit combined with unlimited Flash access and limited Pro access provides maximum capability without friction. Add Claude Pro ($20/month) if you need unlimited daily usage. Total cost: $20/month for essentially unlimited access to two different powerful models.
For Content Creators and Writers:
Claude Pro ($20/month) offers the best writing quality, particularly for long-form content, essay generation, and editorial work. Claude’s writing style is more naturally nuanced than competitors, and the 25-message daily free tier (plus 5x usage with Pro) provides continuous workflow. If you need cutting-edge reasoning for complex concepts, add ChatGPT Plus ($20/month) for the specific reasoning tasks. Total cost: $20-40/month.
For Software Developers:
Claude Pro ($20/month) for everyday coding, combined with DeepSeek-R1 locally for cost-free advanced reasoning during development. The combination provides near-unlimited capability while keeping costs minimal. If you’re building production systems, add ChatGPT Plus ($20/month) for the slight coding edge on complex projects. For APIs, use Gemini 2.5 Flash for high-volume, routine tasks and Claude Sonnet 4.5 for reasoning-intensive work.
For Researchers and Academics:
Google One AI Pro ($19.99/month) unlocks Gemini 2.5 Pro’s 1 million token context window, enabling complete paper/thesis analysis in single sessions. This is irreplaceable for literature review at scale. Add Claude Pro ($20/month) as a secondary research assistant for unique perspective and cross-validation of analysis. Total cost: $40/month for research-grade AI capability.
For Small Businesses:
Start free: Use free tiers of ChatGPT, Claude, and Gemini for experimentation to determine your actual workflow. Once you’ve identified where AI adds value, invest in one primary paid subscription ($20-40/month) rather than paying for multiple premium tiers you won’t use. Most small businesses generate ROI on just one assistant’s time savings within weeks.
For Enterprises:
Negotiate API contracts directly with providers (OpenAI, Google, Anthropic) rather than using consumer subscriptions. Enterprise agreements provide volume discounts, SLAs, custom support, and dedicated compute that justify the negotiation complexity. For reasoning-intensive tasks, use Claude Opus 4.1 despite its premium pricing ($15/$75 per million tokens). For high-volume commodity tasks (customer service, routine analysis), use Gemini 2.5 Flash.
Free vs Pro: The Real Difference in 2025
The most important insight is this: the quality gap between free and pro tiers has collapsed. In 2024, free versions used outdated models. In 2025, free versions often use the same flagship models as paid tiers, with artificial restrictions (message limits, rate limiting) rather than capability limitations.
This changes everything about the cost-benefit equation. A student or freelancer can realistically use only free tiers and get professional-grade AI assistance. The free tiers are genuinely sufficient for 80% of use cases. The $20/month subscription captures the remaining 20%—unlimited usage, priority processing, and marginal capability increases, not a fundamental performance leap.
Looking Ahead: What’s Coming in Late 2025
The competitive intensity continues. OpenAI is expected to launch GPT-4.5 with new “operator” capabilities for autonomous task execution. Anthropic is expanding Claude’s agentic capabilities with longer context windows and improved planning. Google is rolling out Gemini 2.5 Ultra with more advanced reasoning. Alibaba continues Qwen development, with hints that the full Qwen 3 Max release will surpass preview performance.
The trend is obvious: capabilities increase, prices decline or stabilize, and free tiers become increasingly generous. By 2026, current frontier model capability will likely be free or near-free, with the premium tier reserved for exotic features (perfect real-time integration, guaranteed SLAs, etc.) rather than basic performance.
Conclusion: Making Your Decision
As of November 2025, the AI model landscape offers unprecedented value. Choosing between free and pro tiers no longer means sacrificing capability—it means choosing between usage convenience and absolute-latest features. For most people, a strategically chosen free tier supplemented with one $20/month subscription provides everything needed for advanced AI assistance.
The free tier winners are: ChatGPT (GPT-5), Claude (3.5 Sonnet), and Gemini (2.5 Flash)—all genuinely powerful, not just teaser versions. The pro tier that matters most depends on your specific use case: Claude Pro for writing and reasoning, ChatGPT Plus for breadth, Google One AI Pro for long-context research, or Grok for real-time data. The best value play remains DeepSeek-R1, completely free with MIT licensing, achieving near-frontier performance without any restrictions.
The era of expensive, gatekeeping AI has ended. The era of abundant, accessible AI has begun. The question isn’t whether you can afford AI assistance—it’s which AI tool best matches your specific workflow. Test the free tiers. Choose one complementary paid subscription if you need more. Then build your capability around tools optimized for your actual work, not the hype cycle’s latest announcement.